The project aims to provide an interface for users to digitize physical documents. Parallel Archive also hosts and makes these documents publicly available. In our days, the historical imprint of a document is only as credible as its source is traceable. We had to come up with a solution that shows, while anything can happen to data on the internet - we'll know about it every step of the way.
Agile Development - Web Development - IPFS Integration - OCR
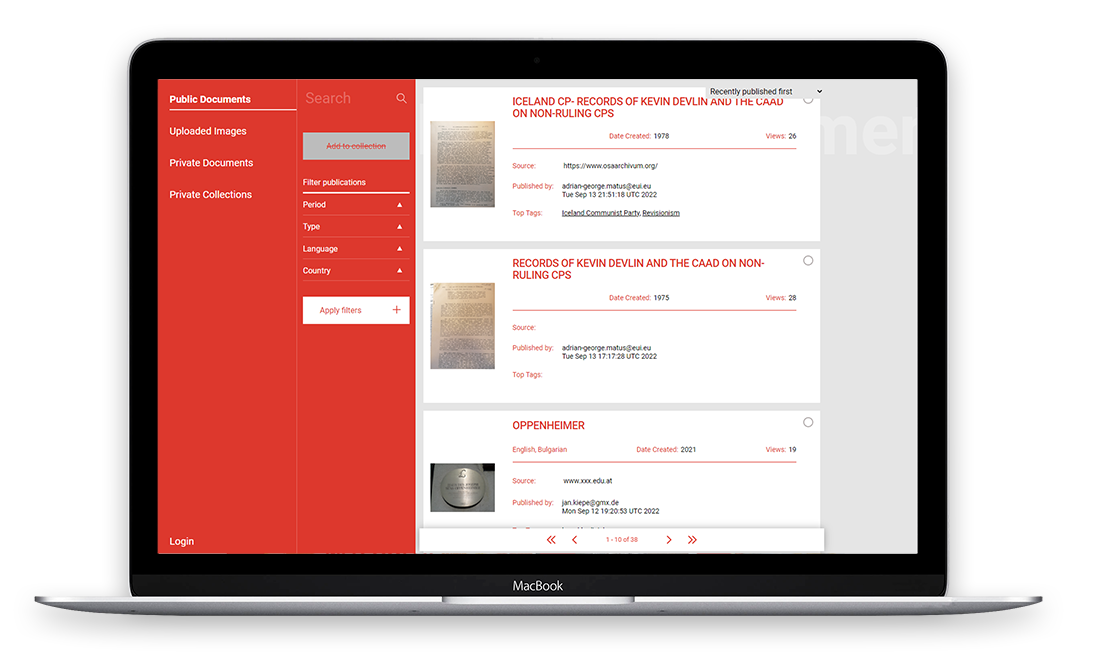
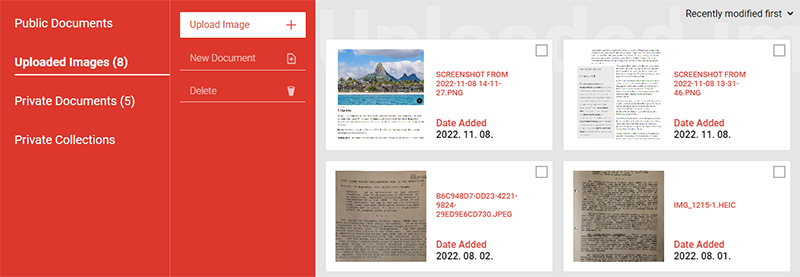
We created a robust online platform where users can manage their account, upload and manage scans of historical documents, compile and share documents based on those scans. Published documents become publicly available in the Parallel Archive. With the use of Optical Character Recognition these documents become highly searchable for researchers browsing the archive and are backed up in multiple locations. Using IPFS we ensure data integrity and availability while allowing users to participate in the backup process in a distributed, decentralized way. By giving special attention to UX on mobile devices we created a streamlined experience for researchers compiling these documents.
Java SpringBoot - Thymeleaf - IPFS - TypeScript - LitHTML - Google Vision OCR - Elasticsearch - Kibana - Prometheus